A company uses ML models to predict whether transactions are fraudulent. The company needs to identify as many fraudulent transactions as possible. Which evaluation metric should the company use to evaluate the models to meet this requirement?
An ML engineer is using an Amazon SageMaker AI shadow test to evaluate a new model that is hosted on a SageMaker AI endpoint. The shadow test requires significant GPU resources for high performance. The production variant currently runs on a less powerful instance type.
The ML engineer needs to configure the shadow test to use a higher performance instance type for a shadow variant. The solution must not affect the instance type of the production variant.
Which solution will meet these requirements?
An ML engineer is training an ML model to identify medical patients for disease screening. The tabular dataset for training contains 50,000 patient records: 1,000 with the disease and 49,000 without the disease.
The ML engineer splits the dataset into a training dataset, a validation dataset, and a test dataset.
What should the ML engineer do to transform the data and make the data suitable for training?
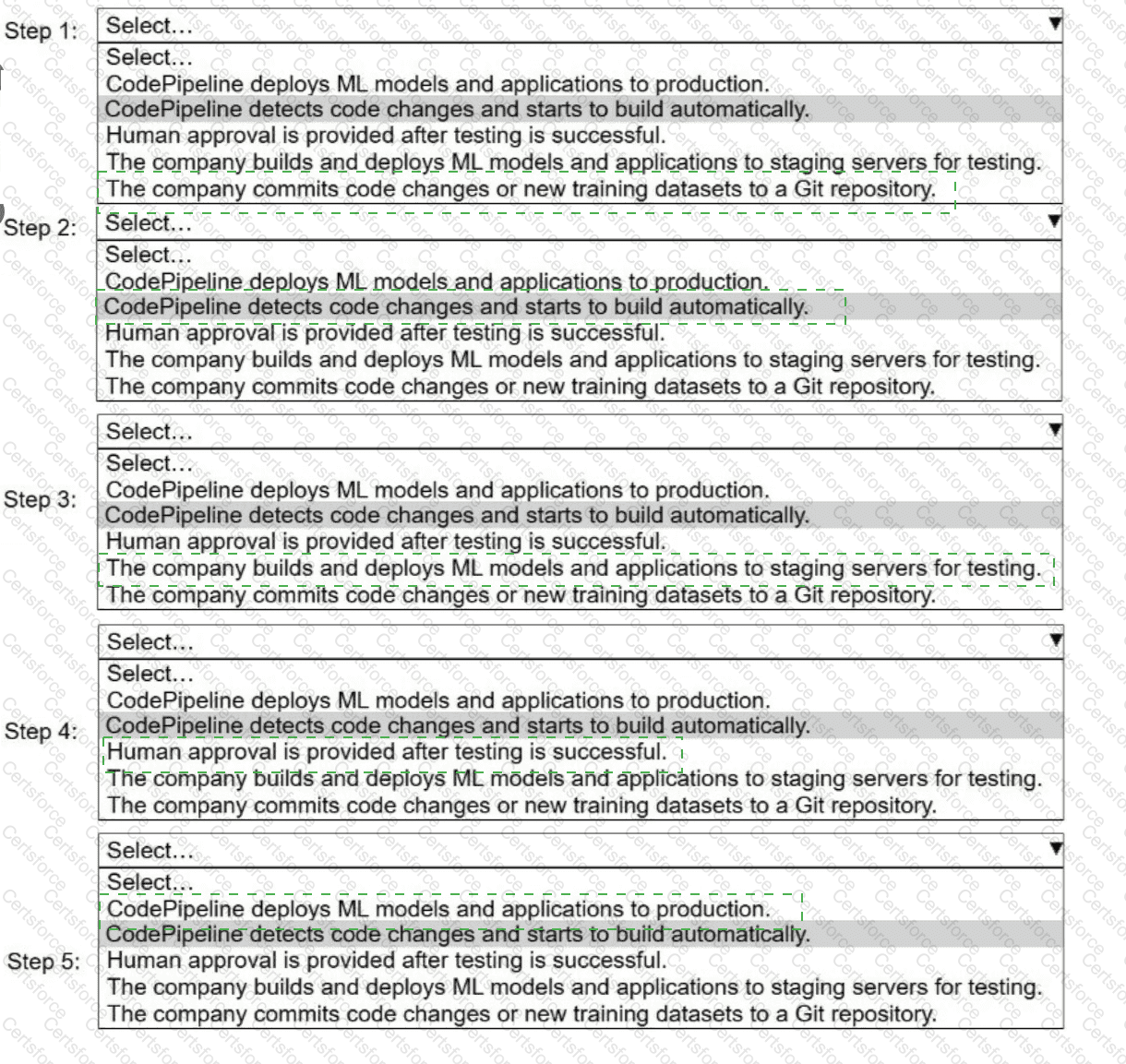
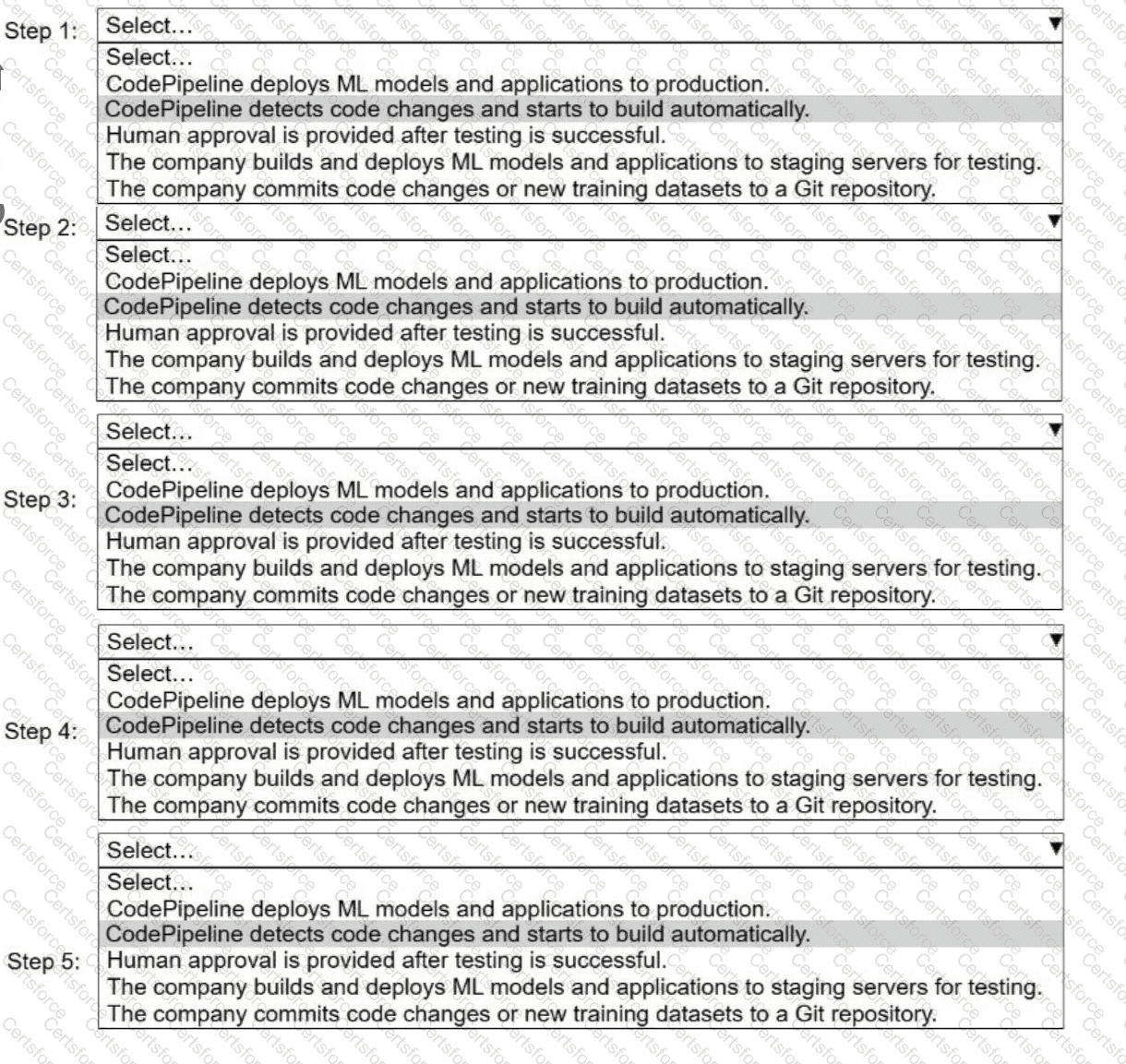
A company uses AWS CodePipeline to orchestrate a continuous integration and continuous delivery (CI/CD) pipeline for ML models and applications.
Select and order the steps from the following list to describe a CI/CD process for a successful deployment. Select each step one time. (Select and order FIVE.)
. CodePipeline deploys ML models and applications to production.
· CodePipeline detects code changes and starts to build automatically.
. Human approval is provided after testing is successful.
. The company builds and deploys ML models and applications to staging servers for testing.
. The company commits code changes or new training datasets to a Git repository.
A company uses a training job on Amazon SageMaker Al to train a neural network. The job first trains a model and then evaluates the model ' s performance ag
test dataset. The company uses the results from the evaluation phase to decide if the trained model will go to production.
The training phase takes too long. The company needs solutions that can shorten training time without decreasing the model ' s final performance.
Select the correct solutions from the following list to meet the requirements for each description. Select each solution one time or not at all. (Select THREE.)
. Change the epoch count.
. Choose an Amazon EC2 Spot Fleet.
· Change the batch size.
. Use early stopping on the training job.
· Use the SageMaker Al distributed data parallelism (SMDDP) library.
. Stop the training job.

An ML engineer is building a model to predict house and apartment prices. The model uses three features: Square Meters, Price, and Age of Building. The dataset has 10,000 data rows. The data includes data points for one large mansion and one extremely small apartment.
The ML engineer must perform preprocessing on the dataset to ensure that the model produces accurate predictions for the typical house or apartment.
Which solution will meet these requirements?
A company has trained an ML model that is packaged in a container. The company will integrate the model with an existing Python web application. The company needs to host the model on AWS by using Kubernetes.
The company does not want to manage the control plane and must provision the resources in a repeatable manner. The infrastructure must be provisioned by using Python.
Which solution will meet these requirements?
A music streaming company constantly streams song ratings from an application to an Amazon S3 bucket. The company wants to use the ratings as an input for training and inference of an Amazon SageMaker AI model.
The company has an AWS Glue Data Catalog that is configured with the S3 bucket as the source. An ML engineer needs to implement a solution to create a repository for this data. The solution must ensure that the data stays synchronized during batch training and real-time inference.
Which solution will meet these requirements?
A company has an application that uses different APIs to generate embeddings for input text. The company needs to implement a solution to automatically rotate the API tokens every 3 months.
Which solution will meet this requirement?
An ML engineer is training a simple neural network model. The model’s performance improves initially and then degrades after a certain number of epochs.
Which solutions will mitigate this problem? (Select TWO.)