A company uses AWS CodePipeline to orchestrate a continuous integration and continuous delivery (CI/CD) pipeline for ML models and applications.
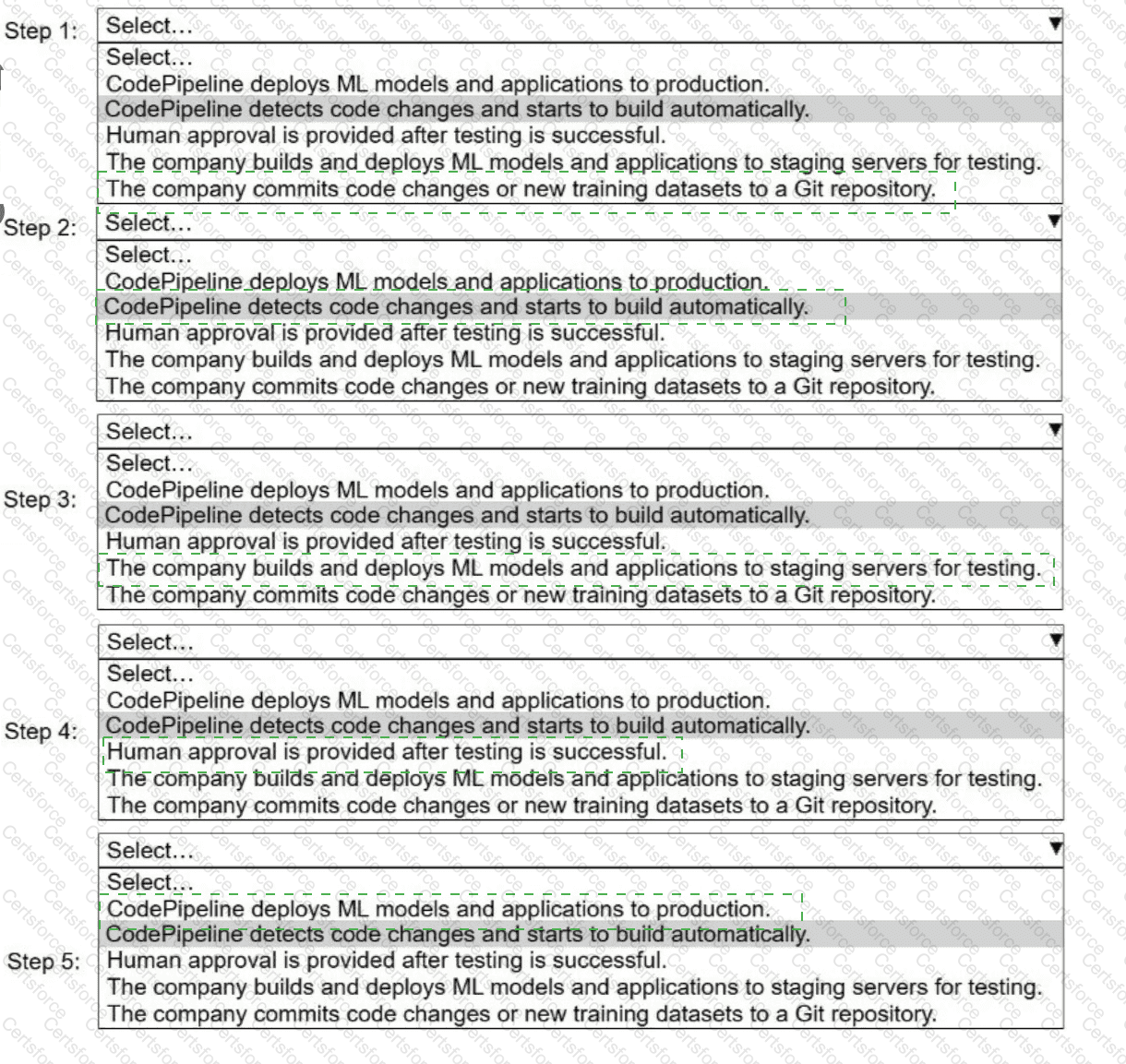
Select and order the steps from the following list to describe a CI/CD process for a successful deployment. Select each step one time. (Select and order FIVE.)
. CodePipeline deploys ML models and applications to production.
· CodePipeline detects code changes and starts to build automatically.
. Human approval is provided after testing is successful.
. The company builds and deploys ML models and applications to staging servers for testing.
. The company commits code changes or new training datasets to a Git repository.
Submit