11 of 55.
Which Spark configuration controls the number of tasks that can run in parallel on an executor?
13 of 55.
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:
region_id
region_name
10
North
12
East
14
West
The resulting Python dictionary must contain a mapping of region_id to region_name, containing the smallest 3 region_id values.
Which code fragment meets the requirements?
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
27 of 55.
A data engineer needs to add all the rows from one table to all the rows from another, but not all the columns in the first table exist in the second table.
The error message is:
AnalysisException: UNION can only be performed on tables with the same number of columns.
The existing code is:
au_df.union(nz_df)
The DataFrame au_df has one extra column that does not exist in the DataFrame nz_df, but otherwise both DataFrames have the same column names and data types.
What should the data engineer fix in the code to ensure the combined DataFrame can be produced as expected?
What is the difference between df.cache() and df.persist() in Spark DataFrame?
Given a DataFrame df that has 10 partitions, after running the code:
result = df.coalesce(20)
How many partitions will the result DataFrame have?
A data engineer wants to write a Spark job that creates a new managed table. If the table already exists, the job should fail and not modify anything.
Which save mode and method should be used?
Given the schema:

event_ts TIMESTAMP,
sensor_id STRING,
metric_value LONG,
ingest_ts TIMESTAMP,
source_file_path STRING
The goal is to deduplicate based on: event_ts, sensor_id, and metric_value.
Options:
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0. The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?

A)

B)
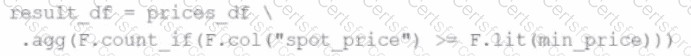
C)
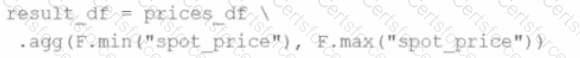
D)

A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?