Your client is interested in ingested the below file to a new generic data stream type:

The field ‘Meeting Code’ was mapped to the main entity key. ‘How should the ‘Room Number’ be mapped?
An implementation engineer is requested to extract the first three-letter segment of the Campaign Name values.
For example:
Campaign Name: AFD@Mulop-1290
Desired outcome: AFD
Other examples:
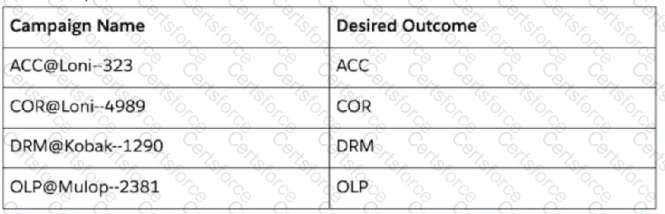
Which formula will return the desired values?
An implementation engineer is requested to create the harmonization field - Magician
This field should come from multiple Twitter Ads data streams, and should follow the below logic:

Using the Harmonization Center, the engineer created a single Pattern for Campaign Name. What other action should the engineer take to meet the requirements?
A technical architect is provided with the logic and Opportunity file shown below:
The opportunity status logic is as follows:
For the opportunity stages “Interest”, “Confirmed Interest” and “Registered”, the status should be “Open”.
For the opportunity stage “Closed”, the opportunity status should be closed
Otherwise, return null for the opportunity status.
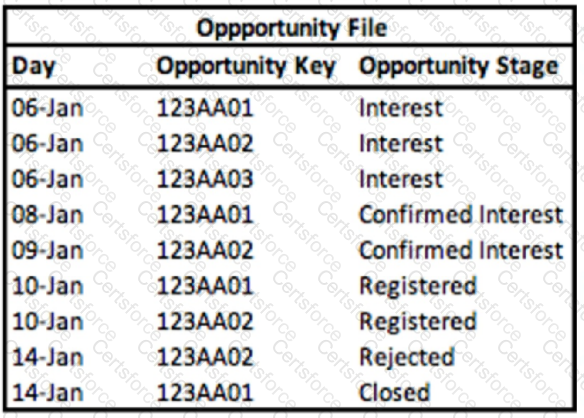
Given the above file and logic and assuming that the file is mapped in a GENERIC data stream type with the following mapping
“Day” — Standard “Day” field
“Opportunity Key” > Main Generic Entity Key
“Opportunity Stage” — Main Generic Entity Attribute
“Opportunity Count” — Generic Custom Metric
A pivot table was created to present the count of opportunities in each stage. The pivot table is filtered on Jan 11th. What is the number of ‘opportunities in the Confirmed Interest stage?
A client has provided you with sample files of their data from the following data sources:
1.Google Analytics
2.Salesforce Marketing Cloud
The link between these sources is on the following two fields:
Message Send Key
A portion of: web_site_source_key
Below is the logic the client would like to have implemented in Datorama:
For ‘web site medium’ values containing the word “email” (in all of its forms), the section after the “_” delimiter in ‘web_site_source_key’ is a 4 digit
number, which matches the 'Message Send Key’ values from the Salesforce Marketing Cloud file. Possible examples of this can be seen in the
following table:
Google Analytics:

Salesforce Marketing Cloud:

The client's objective is to visualize the mutual key values alongside measurements from both files in a table.

In order to achieve this, what steps should be taken?
The following file was uploaded into Marketing Cloud Intelligence as a generic dataset type:

The mapping is as follows:
Day — Day
Web_site_source — Main Generic Entity Attribute 01
Page Views — Generic Metric 1
*Note that ‘web_site_key’ and ‘web_site_name’ are NOT mapped.
How many rows will be stored in Marketing Cloud Intelligence after the above file is ingested?
What are unstable measurements?
A technical architect is provided with the logic and Opportunity file shown below:
The opportunity status logic is as follows:
For the opportunity stages “Interest”, “Confirmed Interest” and “Registered”, the status should be “Open”.
For the opportunity stage “Closed”, the opportunity status should be closed.
Otherwise, return null for the opportunity status.
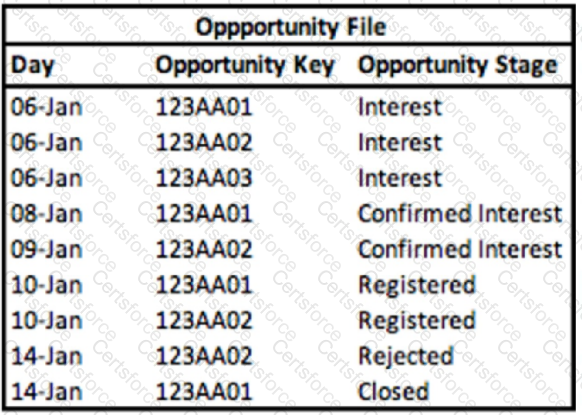
Given the above file and logic and assuming that the file is mapped in a GENERIC data stream type with the following mapping:
“Day” — Standard “Day” field
“Opportunity Key” > Main Generic Entity Key
“Opportunity Stage” — Generic Entity Key 2
“Opportunity Count” — Generic Custom Metric
A pivot table was created to present the count of opportunities in each stage. The pivot table is filtered on Jan 7th - 10th. How many different stages are presented in the table?
A client created a new KPI: CPS (Cost per Sign-up).
The new KIP is mapped within the data stream mapping, and is populated with the following logic: (Media Cost) / Sign-ups)
As can be seen in the table below, CPS was created twice and was set with two different aggregations:

From looking at the table, what are the aggregation settings for each one of the newly created KPIs?
A)

B)

C)

D)

After uploading a standard file into Marketing Cloud intelligence via total Connect, you noticed that the number of rows uploaded (to the specific data stream) is NOT equal to the number of rows present in the source file. What are two resource that may cause this gap?