A data engineer is configuring Delta Sharing for a Databricks-to-Databricks scenario to optimize read performance. The recipient needs to perform time travel queries and streaming reads on shared sales data.
Which configuration will provide the optimal performance while enabling these capabilities?
A data engineer is designing a Lakeflow Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id and amount are greater than zero. Invalid records should be dropped.
Which Lakeflow Declarative Pipelines configurations implement this requirement using Python?
The data governance team is reviewing user for deleting records for compliance with GDPR. The following logic has been implemented to propagate deleted requests from the user_lookup table to the user aggregate table.

Assuming that user_id is a unique identifying key and that all users have requested deletion have been removed from the user_lookup table, which statement describes whether successfully executing the above logic guarantees that the records to be deleted from the user_aggregates table are no longer accessible and why?
The data engineer team is configuring environment for development testing, and production before beginning migration on a new data pipeline. The team requires extensive testing on both the code and data resulting from code execution, and the team want to develop and test against similar production data as possible.
A junior data engineer suggests that production data can be mounted to the development testing environments, allowing pre production code to execute against production data. Because all users have
Admin privileges in the development environment, the junior data engineer has offered to configure permissions and mount this data for the team.
Which statement captures best practices for this situation?
A Spark job is taking longer than expected. Using the Spark UI, a data engineer notes that the Min, Median, and Max Durations for tasks in a particular stage show the minimum and median time to complete a task as roughly the same, but the max duration for a task to be roughly 100 times as long as the minimum.
Which situation is causing increased duration of the overall job?
A data engineering team uses Databricks Lakehouse Monitoring to track the percent_null metric for a critical column in their Delta table.
The profile metrics table (prod_catalog.prod_schema.customer_data_profile_metrics) stores hourly percent_null values.
The team wants to:
Trigger an alert when the daily average of percent_null exceeds 5% for three consecutive days .
Ensure that notifications are not spammed during sustained issues.
Options:
Given the following error traceback (from display(df.select(3* " heartrate " ))) which shows AnalysisException: cannot resolve ' heartrateheartrateheartrate ' , which statement describes the error being raised?
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function will automatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected.
The function is displayed below with a blank:

Which response correctly fills in the blank to meet the specified requirements?

The Databricks CLI is used to trigger a run of an existing job by passing the job_id parameter. The response indicating the job run request was submitted successfully includes a field run_id. Which statement describes what the number alongside this field represents?
The data science team has created and logged a production model using MLflow. The following code correctly imports and applies the production model to output the predictions as a new DataFrame named preds with the schema " customer_id LONG, predictions DOUBLE, date DATE " .
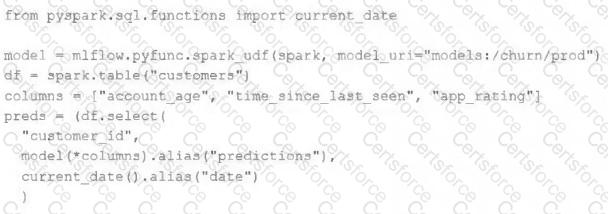
The data science team would like predictions saved to a Delta Lake table with the ability to compare all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
preds.write.mode( " append " ).saveAsTable( " churn_preds " )
preds.write.format( " delta " ).save( " /preds/churn_preds " )
C)

D)
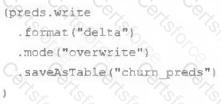
E)
Option A
Option B
Option C
Option D
Option E
