A Spark application is experiencing performance issues in client mode because the driver is resource-constrained.
How should this issue be resolved?
An engineer wants to join two DataFramesdf1anddf2on the respectiveemployee_idandemp_idcolumns:
df1:employee_id INT,name STRING
df2:emp_id INT,department STRING
The engineer uses:
result = df1.join(df2, df1.employee_id == df2.emp_id, how='inner')
What is the behaviour of the code snippet?
A developer runs:
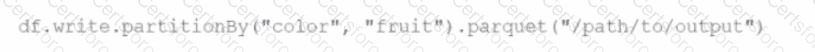
What is the result?
Options:
Which Spark configuration controls the number of tasks that can run in parallel on the executor?
Options:
A data engineer needs to write a DataFramedfto a Parquet file, partitioned by the columncountry, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?