An engineer has a large ORC file located at/file/test_data.orcand wants to read only specific columns to reduce memory usage.
Which code fragment will select the columns, i.e.,col1,col2, during the reading process?
Given a DataFramedfthat has 10 partitions, after running the code:
result = df.coalesce(20)
How many partitions will the result DataFrame have?
A data engineer is working with a large JSON dataset containing order information. The dataset is stored in a distributed file system and needs to be loaded into a Spark DataFrame for analysis. The data engineer wants to ensure that the schema is correctly defined and that the data is read efficiently.
Which approach should the data scientist use to efficiently load the JSON data into a Spark DataFrame with a predefined schema?
A developer initializes a SparkSession:

spark = SparkSession.builder \
.appName("Analytics Application") \
.getOrCreate()
Which statement describes thesparkSparkSession?
The following code fragment results in an error:
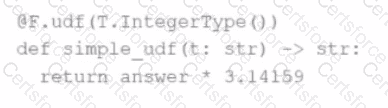
Which code fragment should be used instead?
A)

B)

C)

D)

A Spark engineer must select an appropriate deployment mode for the Spark jobs.
What is the benefit of using cluster mode in Apache Spark™?
What is the benefit of using Pandas on Spark for data transformations?
Options:
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior?
Choose 2 answers:
A data scientist has identified that some records in the user profile table contain null values in any of the fields, and such records should be removed from the dataset before processing. The schema includes fields like user_id, username, date_of_birth, created_ts, etc.
The schema of the user profile table looks like this:

Which block of Spark code can be used to achieve this requirement?
Options:
A data engineer is running a Spark job to process a dataset of 1 TB stored in distributed storage. The cluster has 10 nodes, each with 16 CPUs. Spark UI shows:
Low number of Active Tasks
Many tasks complete in milliseconds
Fewer tasks than available CPUs
Which approach should be used to adjust the partitioning for optimal resource allocation?