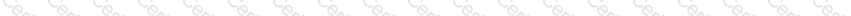Match the testing tool with the type of test it is typically used to perform.
(You deploy a Kafka Streams application with five application instances.
Kafka Streams stores application metadata using internal topics.
Auto-topic creation is disabled in the Kafka cluster.
Which statement about this scenario is true?)
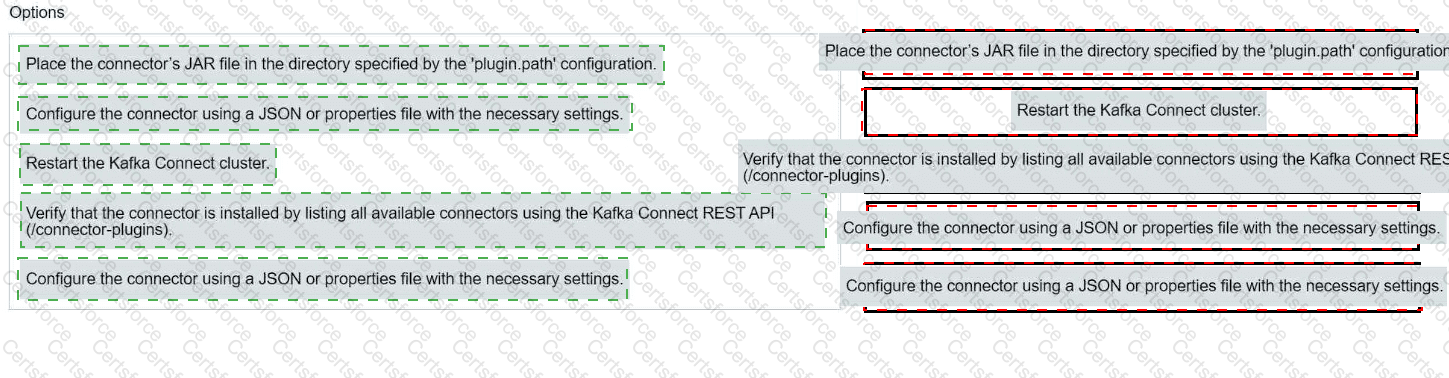
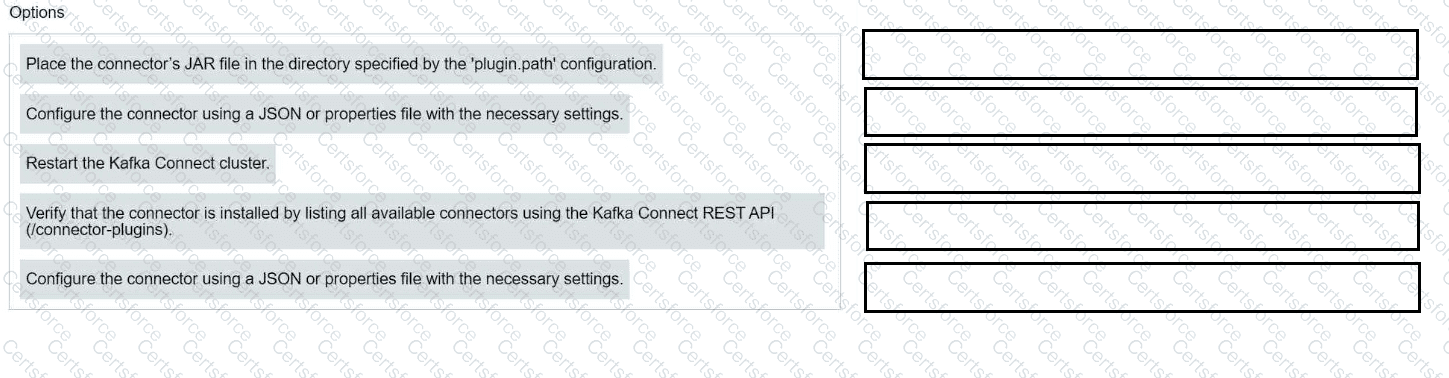
Match each configuration parameter with the correct deployment step in installing a Kafka connector.
You are experiencing low throughput from a Java producer.
Metrics show low I/O thread ratio and low I/O thread wait ratio.
What is the most likely cause of the slow producer performance?
(Your application consumes from a topic configured with a deserializer.
You want the application to be resilient to badly formatted records (poison pills).
You surround the poll() call with a try/catch block for RecordDeserializationException.
You need to log the bad record, skip it, and continue processing other records.
Which action should you take in the catch block?)
You use Kafka Connect with the JDBC source connector to extract data from a large database and push it into Kafka.
The database contains tens of tables, and the current connector is unable to process the data fast enough.
You add more Kafka Connect workers, but throughput doesn't improve.
What should you do next?
This schema excerpt is an example of which schema format?
package com.mycorp.mynamespace;
message SampleRecord {
int32 Stock = 1;
double Price = 2;
string Product_Name = 3;
}