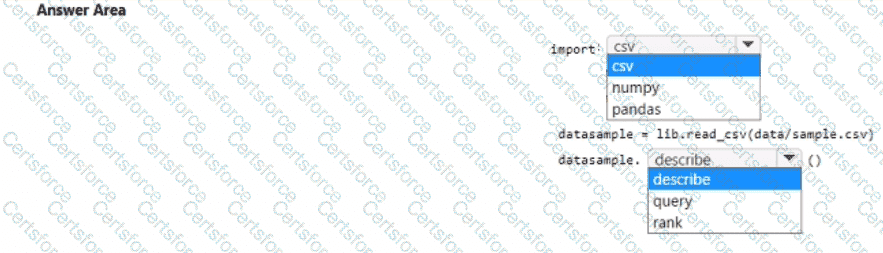A biomedical research company plans to enroll people in an experimental medical treatment trial.
You create and train a binary classification model to support selection and admission of patients to the trial. The model includes the following features: Age, Gender, and Ethnicity.
The model returns different performance metrics for people from different ethnic groups.
You need to use Fairlearn to mitigate and minimize disparities for each category in the Ethnicity feature.
Which technique and constraint should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Your team is building a data engineering and data science development environment.
The environment must support the following requirements:
support Python and Scala
compose data storage, movement, and processing services into automated data pipelines
the same tool should be used for the orchestration of both data engineering and data science
support workload isolation and interactive workloads
enable scaling across a cluster of machines
You need to create the environment.
What should you do?
You download a .csv file from a notebook in an Azure Machine Learning workspace to a data/sample.csv folder on a compute instance. The file contains 10,000 records. You must generate the summary statistics for the data in the file. The statistics must include the following for each numerical column:
• number of non-empty values
• average value
• standard deviation
• minimum and maximum values
• 25th. 50th. and 75th percentiles
You need to complete the Python code that will generate the summary statistics.
Which code segments should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.