Which of the following is hosted completely in the control plane of the classic Databricks architecture?
The Delta transaction log for the ‘students’ tables is shown using the ‘DESCRIBE HISTORY students’ command. A Data Engineer needs to query the table as it existed before the UPDATE operation listed in the log.
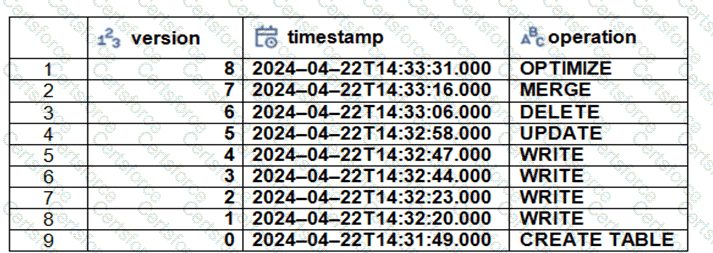
Which command should the Data Engineer use to achieve this? (Choose two.)
A data engineer has been provided a PySpark DataFrame named df with columns product and revenue. The data engineer needs to compute complex aggregations to determine each product ' s total revenue, average revenue, and transaction count.
Which code snippet should the data engineer use?
A)
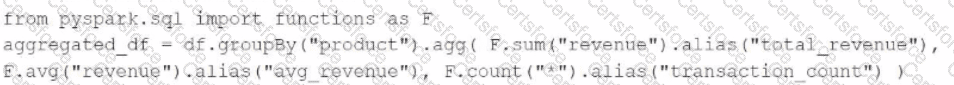
B)

C)

D)

A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
A)
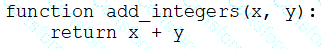
B)

C)
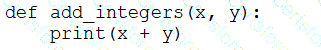
D)
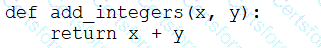
E)
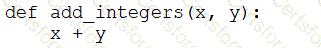
Which method should a Data Engineer apply to ensure Workflows are being triggered on schedule?
A data engineer streams customer orders into a Kafka topic (orders_topic) and is currently writing the ingestion script of a DLT pipeline. The data engineer needs to ingest the data from Kafka brokers to DLT using Databricks
What is the correct code for ingesting the data?
A)

B)
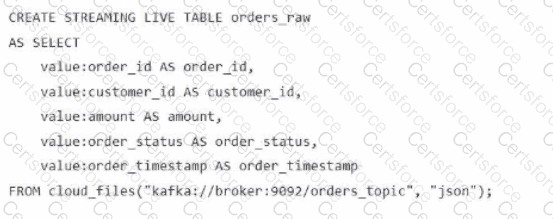
C)

D)

In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
A data engineering project involves processing large batches of data on a daily schedule using ETL. The jobs are resource-intensive and vary in size, requiring a scalable, cost-efficient compute solution that can automatically scale based on the workload.
Which compute approach will satisfy the needs described?
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team’s queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team’s queries?
Which of the following describes when to use the CREATE STREAMING LIVE TABLE (formerly CREATE INCREMENTAL LIVE TABLE) syntax over the CREATE LIVE TABLE syntax when creating Delta Live Tables (DLT) tables using SQL?