You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
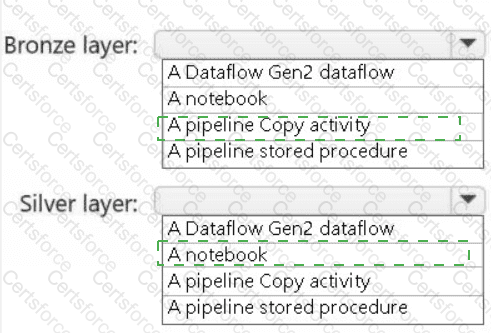
You need to recommend a method to populate the POS1 data to the lakehouse medallion layers.
What should you recommend for each layer? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

You need to ensure that WorkspaceA can be configured for source control. Which two actions should you perform?
Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You need to recommend a solution for handling old files. The solution must meet the technical requirements. What should you include in the recommendation?
You have a Fabric notebook named Notebook1 that has been executing successfully for the last week.
During the last run, Notebook1executed nine jobs.
You need to view the jobs in a timeline chart.
What should you use?
You need to ensure that the data engineers are notified if any step in populating the lakehouses fails. The solution must meet the technical requirements and minimize development effort.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
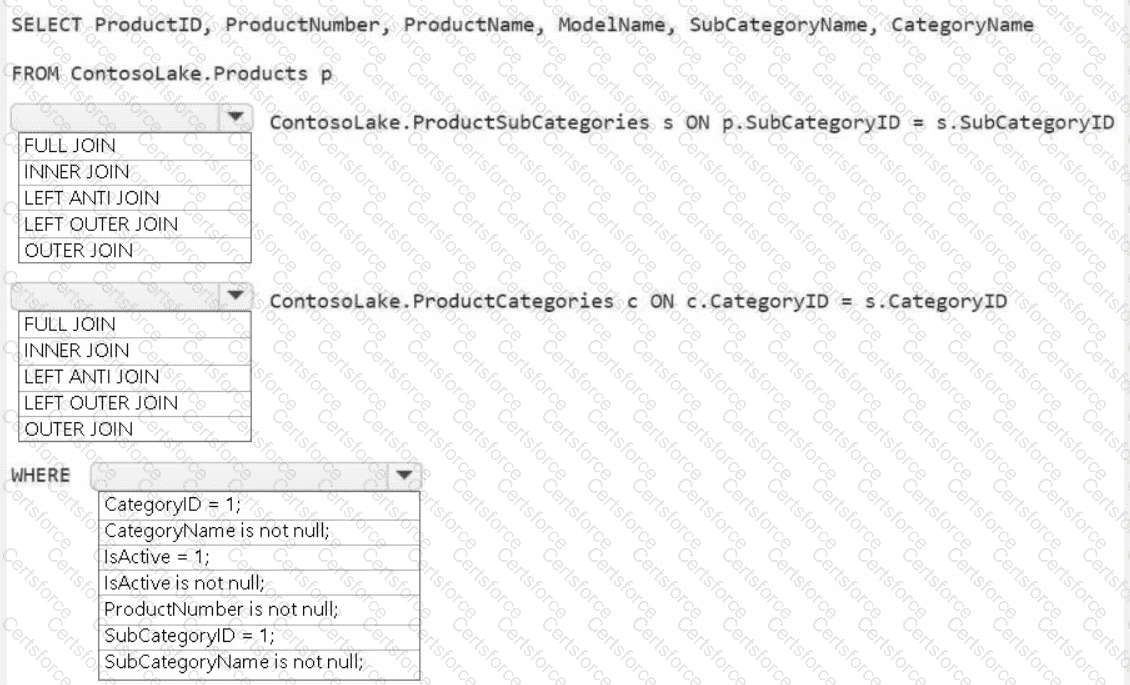
You need to populate the MAR1 data in the bronze layer.
Which two types of activities should you include in the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
You have a Fabric tenant that is linked to a Microsoft Entra tenant. The Microsoft [intra tenant contains a user named User1 and two groups named Group! and Groups.
The Fabric tenant contains the workspaces shown in the following table.

You need to meet the following access requirements:
• User1 must have read access to the following:
• The operations department reports
• The HR department warehouse and reports
• The legal department warehouse and reports
• User1 must be able to create new items in Workspace
• Group1 must have access to the finance department warehouse and reports.
• Group1 must be able to add new users to the finance department workspace.
• Group2 must have access to only the HR warehouse and the legal warehouse.
The solution must follow the principle of least privilege.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

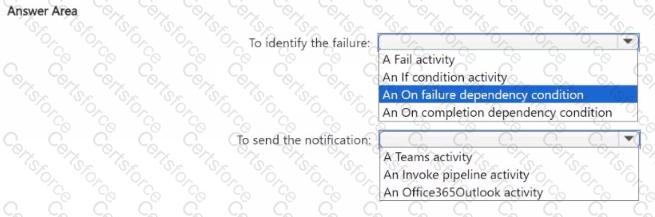
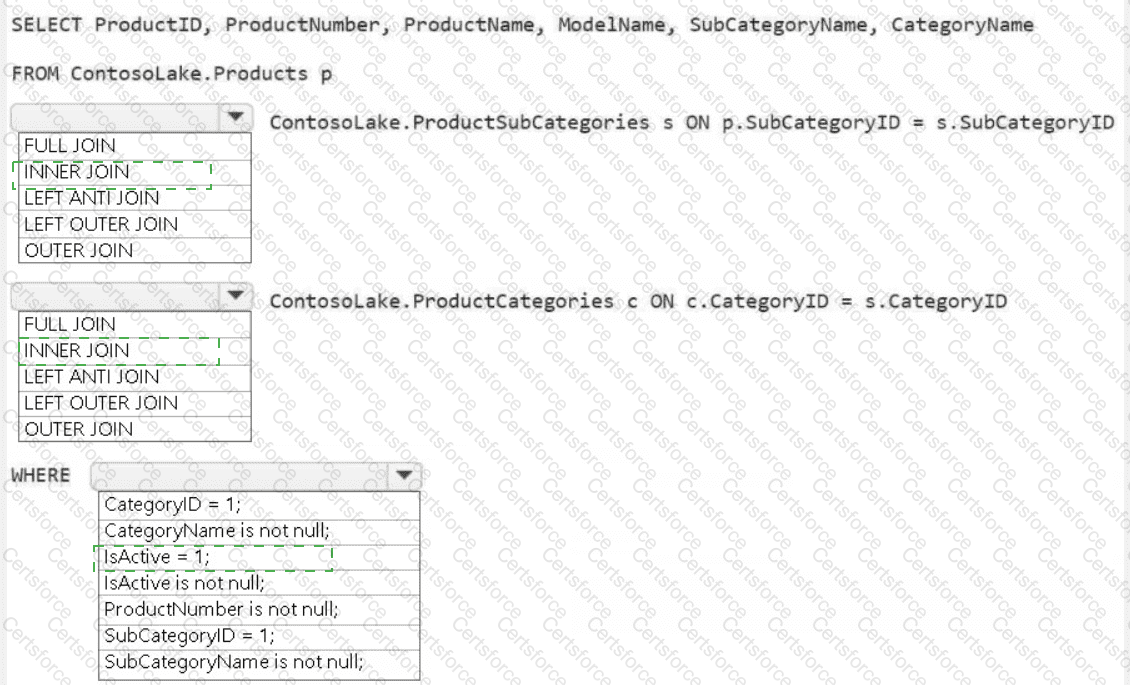
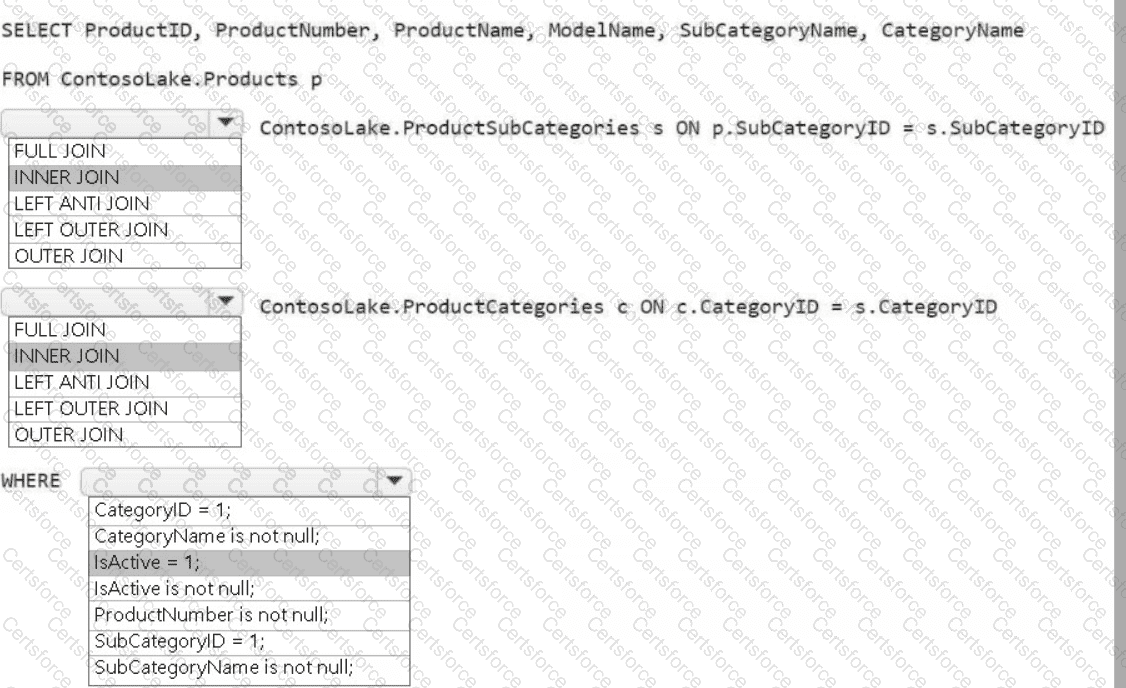
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generated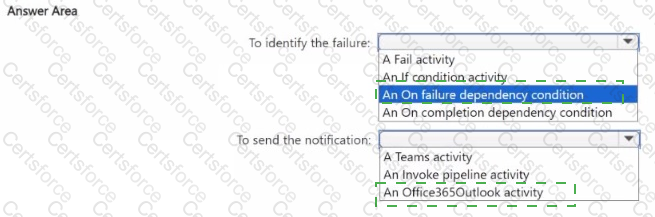

 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generated