Which two statements are correct about deploying machine learning models? (Choose two.)
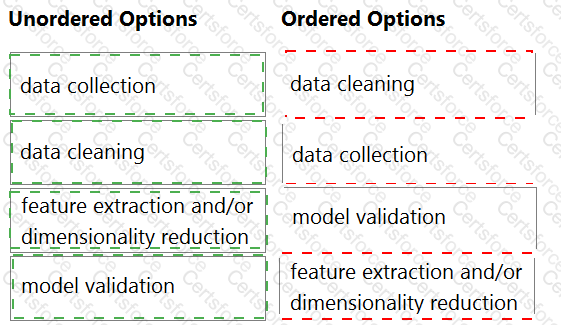
What is the best step by step order for machine learning pipeline?

Which IBM Watson Machine Learning deployment method offers the ultimate flexibility in deploying a machine learning model?
What is the meaning of "deep" in deep learning?
What are three elements that are typically part of a machine learning pipeline in scikit-learn or pyspark? (Choose three.)
What are the various components that make up a time series data?
Considering one ML application is deployed using Kubernetes, its output depends on the data which is constantly stored in the model, if needing to scale the system based on available CPUs, what feature should be enabled?
Which test is applied to determine the relationship between two categorical variables?