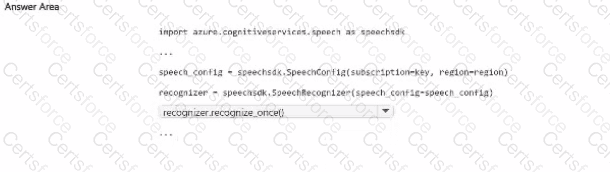
The correct Python method is:
recognizer.recognize_once()
Completed code:
import azure.cognitiveservices.speech as speechsdk
speech_config = speechsdk.SpeechConfig(subscription=key, region=region)
recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
recognizer.recognize_once()
Microsoft’s Azure Speech documentation for Foundry Tools explains that Speech to text is used for real-time speech recognition and converting spoken audio into text. The Python Speech SDK uses a SpeechRecognizer object for recognition from audio input, such as a microphone.
Why the other options are incorrect:
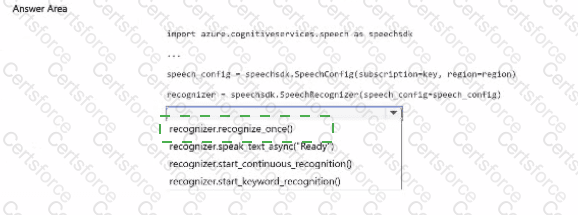
recognizer.speak_text_async("Ready") is incorrect because speaking text is text-to-speech , not speech-to-text recognition.
recognizer.start_continuous_recognition() can be used for continuous recognition, but the code shown is asking for the basic method to recognize spoken input and convert it to text from the SpeechRecognizer.
recognizer.start_keyword_recognition() is used for keyword/wake-word recognition, not general speech-to-text transcription of spoken commands.
Therefore, the correct answer is:
recognizer.recognize_once()

Submit