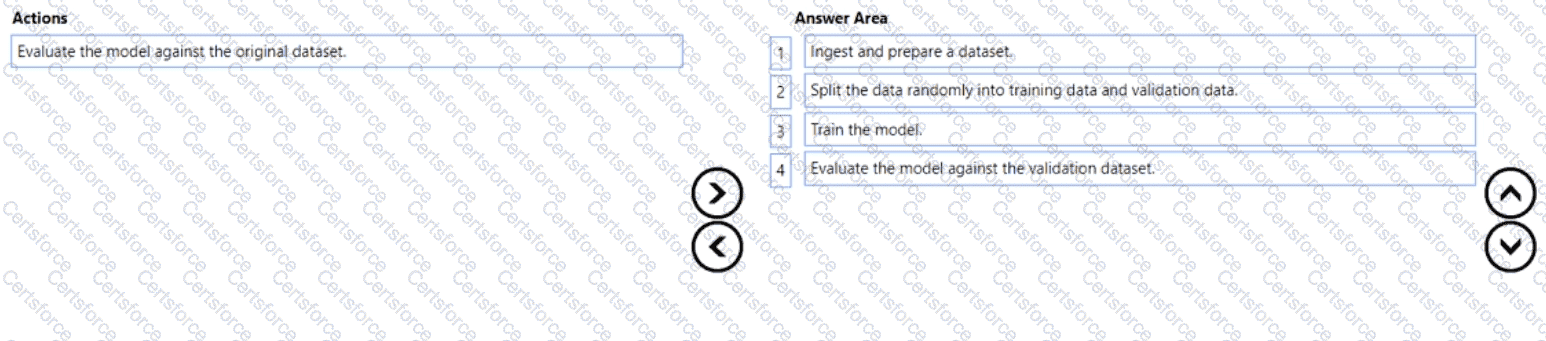
You plan to deploy an Azure Machine Learning model by using the Machine Learning designer
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


Submit