A data scientist wants to efficiently tune the hyperparameters of a scikit-learn model. They elect to use the Hyperopt library'sfminoperation to facilitate this process. Unfortunately, the final model is not very accurate. The data scientist suspects that there is an issue with theobjective_functionbeing passed as an argument tofmin.
They use the following code block to create theobjective_function:

Which of the following changes does the data scientist need to make to theirobjective_functionin order to produce a more accurate model?
A machine learning engineer is using the following code block to scale the inference of a single-node model on a Spark DataFrame with one million records:

Assuming the default Spark configuration is in place, which of the following is a benefit of using anIterator?
A data scientist has produced three new models for a single machine learning problem. In the past, the solution used just one model. All four models have nearly the same prediction latency, but a machine learning engineer suggests that the new solution will be less time efficient during inference.
In which situation will the machine learning engineer be correct?
Which of the following describes the relationship between native Spark DataFrames and pandas API on Spark DataFrames?
A machine learning engineer wants to parallelize the inference of group-specific models using the Pandas Function API. They have developed theapply_modelfunction that will look up and load the correct model for each group, and they want to apply it to each group of DataFramedf.
They have written the following incomplete code block:

Which piece of code can be used to fill in the above blank to complete the task?
A machine learning engineer would like to develop a linear regression model with Spark ML to predict the price of a hotel room. They are using the Spark DataFrametrain_dfto train the model.
The Spark DataFrametrain_dfhas the following schema:

The machine learning engineer shares the following code block:
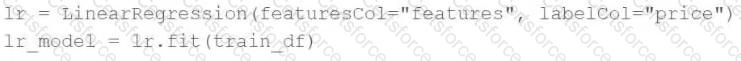
Which of the following changes does the machine learning engineer need to make to complete the task?
A data scientist has written a data cleaning notebook that utilizes the pandas library, but their colleague has suggested that they refactor their notebook to scale with big data.
Which of the following approaches can the data scientist take to spend the least amount of time refactoring their notebook to scale with big data?
In which of the following situations is it preferable to impute missing feature values with their median value over the mean value?
A data scientist uses 3-fold cross-validation when optimizing model hyperparameters for a regression problem. The following root-mean-squared-error values are calculated on each of the validation folds:
• 10.0
• 12.0
• 17.0
Which of the following values represents the overall cross-validation root-mean-squared error?
The implementation of linear regression in Spark ML first attempts to solve the linear regression problem using matrix decomposition, but this method does not scale well to large datasets with a large number of variables.
Which of the following approaches does Spark ML use to distribute the training of a linear regression model for large data?