A large table with 200 columns contains two years of historical data. When queried. the table is filtered on a single day Below is the Query Profile:
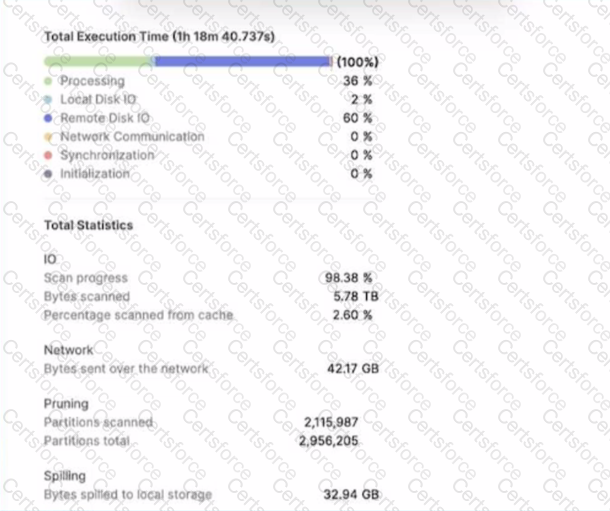
Using a size 2XL virtual warehouse, this query look over an hour to complete
What will improve the query performance the MOST?
A company has an extensive script in Scala that transforms data by leveraging DataFrames. A Data engineer needs to move these transformations to Snowpark.
…characteristics of data transformations in Snowpark should be considered to meet this requirement? (Select TWO)
Which Snowflake objects does the Snowflake Kafka connector use? (Select THREE).
What kind of Snowflake integration is required when defining an external function in Snowflake?
Company A and Company B both have Snowflake accounts. Company A's account is hosted on a different cloud provider and region than Company B's account Companies A and B are not in the same Snowflake organization.
How can Company A share data with Company B? (Select TWO).
A Data Engineer ran a stored procedure containing various transactions During the execution, the session abruptly disconnected preventing one transactionfrom committing or rolling hark.The transaction was left in a detached state and created a lock on resources
...must the Engineer take to immediately run a new transaction?
A Data Engineer has developed a dashboard that will issue the same SQL select clause to Snowflake every 12 hours.
---will Snowflake use the persisted query results from the result cache provided that the underlying data has not changed^
A CSV file around 1 TB in size is generated daily on an on-premise server A corresponding table. Internal stage, and file format have already been created in Snowflake to facilitate the data loading process
How can the process of bringing the CSV file into Snowflake be automated using the LEAST amount of operational overhead?
Which methods can be used to create a DataFrame object in Snowpark? (Select THREE)
Which functions will compute a 'fingerprint' over an entire table, query result, or window to quickly detect changes to table contents or query results? (Select TWO).