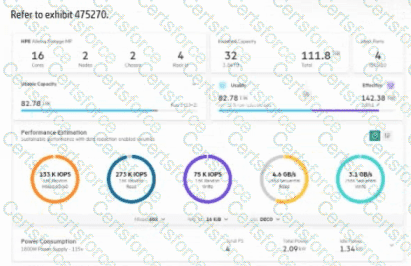
The exhibit shows an Alletra MP configuration delivering ~4.6 GB/s (256 KB sequential read) with four 10 Gb host ports. That throughput is close to the aggregate front-end bandwidth ceiling of 4×10 GbE (≈5 GB/s raw, less with protocol overhead). For large-block sequential workloads, the front-end link budget is often the bottleneck; adding additional 10 GbE ports (or moving to higher-speed links) increases available host bandwidth and raises sustained sequential read throughput. This aligns with HPE sizing guidance: scale host connectivity to meet sequential throughput targets before adding media.
Analysis of Incorrect Options (Distractors):
B: Adding a third node isn’t applicable to a 2-node HA block pair and would not address a front-end bandwidth limit.
C: More controller cores don’t raise link-level throughput if host I/O is already constrained by port bandwidth.
D: Adding NVMe media primarily boosts IOPS/parallelism; sequential read is bounded here by front-end ports.
Key Concept: Sequential throughput is front-end bandwidth bound; scale host ports to increase GB/s.
[Reference: HPE Alletra MP Performance and Sizing best practices (host connectivity scaling for throughput)., ]
Contribute your Thoughts:
Chosen Answer:
This is a voting comment (?). You can switch to a simple comment. It is better to Upvote an existing comment if you don't have anything to add.
Submit