A junior data engineer seeks to leverage Delta Lake ' s Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in a bronze table created with the property delta.enableChangeDataFeed = true . They plan to execute the following code as a daily job:
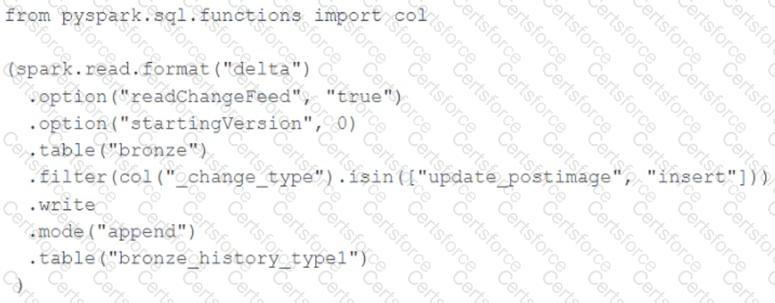
Which statement describes the execution and results of running the above query multiple times?
Submit